K-means vs. DBSCAN
K-means 와 DBSCAN 알고리즘 비교
1. 데이터셋
K-means 와 DBSCAN 알고리즘 비교를 위해 numpy random 함수를 이용하여 간단한 데이터셋을 만들었다.
2. K-means
K-means 알고리즘은 클러스터의 개수를 미리 지정하여야 하기 때문에 n_cluster 를 3 으로 지정하였다.
K_means = KMeans(n_clusters=3, random_state=0)
K_means.fit(X)
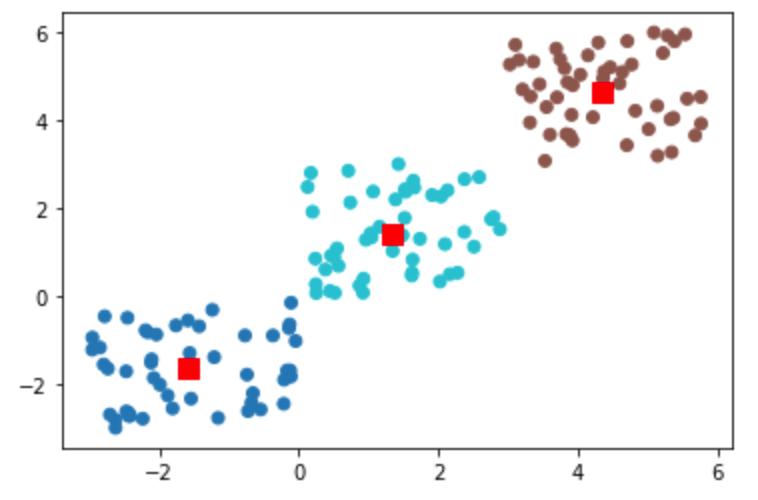
각 클러스터의 중심을 기준으로 클러스터링이 잘 이루어진 모습을 확인할 수 있다.
3. DBSCAN
6개의 (eps, min_samples) 묶음을 준비하여 학습하였고 그 중 가장 성능이 좋은 조합을 발견할 수 있었다.
#enu = ((eps, min_samples))
enu = ((0.5, 3), (0.5, 5), (1, 3), (1, 5), (1.5, 3), (1.5, 5))
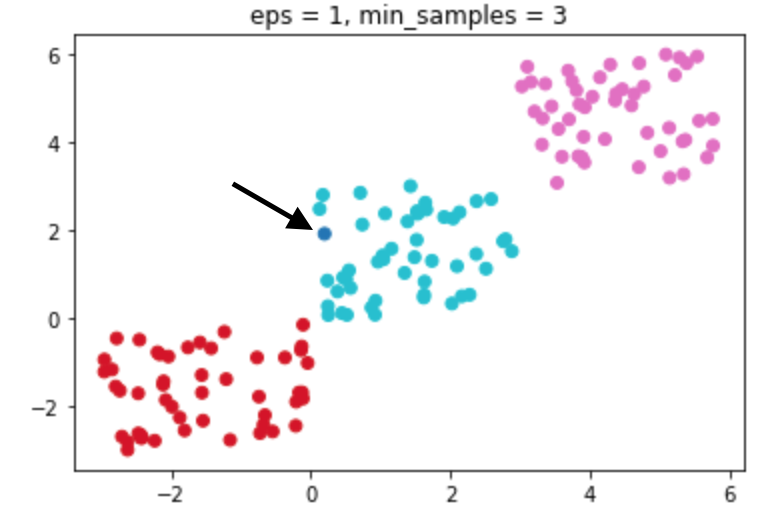
eps = 1, min_samples = 3 일 때 가장 좋은 성능을 보였고 하늘색 클러스터에서 한 개의 이상치(짙은 파란색)를 발견하였다.